Nutanix Objects Replication: High availability, low drama
As always, we start with the obligatory “it’s been a while since my last post”. This time we blame some writing obligations for a publisher in Germany, which should release a few things in the upcoming months. Keep an eye open for those announcements on LinkedIn!
Anyway, back to the topic at hand:
If you hung around for a while, you’ve probably read my first blog on Nutanix Objects and already know i have a soft spot for terrible puns. This time we’re going a little deeper: objects streaming replication. All the availability within a cluster is impressive, but what if things go really sideways? Objects got you covered, highly available, with low drama.
For this little adventure, I’ll use a demo environment with limited scale. This is a single cluster with 4 physical nodes, running 1 Prism Central and multiple object stores. No worries, everything you'll see here also works across multiple clusters and Prism Centrals. We also have a locally running HAproxy, because it was easy to spin up on a Mac and only needed a couple of lines of config. We’ll go about this in two steps. First, we’ll peek under the hood at streaming replication. Then we’ll see how failover plays nice with our HAproxy and the Multi-FQDN feature. By the end, we should be able to query “the same” bucket from a client's perspective, even as we bounce between Object Stores.
The Copy + Paste that never sleeps
First, let us review what “Streaming Replication” means in Nutanix Objects. This technology replicates an object as soon as a S3 PUT request finishes. The setup happens at the bucket level. So, from a setup perspective we have one or more object stores running, in which we create buckets. Those buckets can then be given replication rules, and once that happens, the Objects service wathces for new object being added and streams them to the target.

The object store in this case is called “rfdemo” and the FQDN is rfdemo.prism-central.cluster.local. For a little proof of concept I needed to create lots of objects across multiple buckets, just to see how quickly we could delete large sets of them. That’s why I set up three buckets in here, called “objectsdeletedemo”. To make life easier, I configured replication so that objectsdeletedemo automatically replicated to objectsdeletedemo2 and objectsdeletedemo3.

Here is where it gets interesting. The streaming replication rules are always configured as outgoing replication rules and allow for flexible setups, like 1:n replication. You can “fan out” from one source bucket to as many as three destinations in the current release. Each rule is independent as well. If for some reason I only want to replicate to bucket “objectsdeletedemo3”, I could pause replication to objectsdeletedemo2 while keeping replication active to objectsdeletedemo3. Another neat trick: you can configure bi-directional replication. So if I wanted every new object from “objectsdeletedemo2” to be replicated to “objectsdeletedemo”, I would just add another outgoing replication rule in the opposite direction. To put this to the test, I generated 10,000 objects in the first bucket and watched streaming replication pick them up. In here we can see the details view of an individual outgoing replication, which showed a queue of 167 objects at one point.

In this example, I created 10,000 objects at about 763 objects per second. The main reason that this isn’t higher is latency. The Python script was running on a client in Germany while the Object store was sitting in Nevada. Still, the streaming replication keeps up very well. The effective recovery point objective (RPO) is close to zero. This brings us to another point worth mentioning: RPO expectations. This is not synchronous replication with a guaranteed RPO of 0. Since we only pick up objects once they are done uploading to the first bucket, there will be some delay before the object is done replicating to the second site. In most cases, this is within seconds, but depends on various factors like available bandwidth and object size. Think of it as “RPO-close-to-zero.”
After the script created 10,000 objects, increasing the total count in the bucket to 110k objects, both destination buckets showed the same object count almost immediately afterward.

All of this is great, but how do we access the bucket and how do we switch between object stores? Nutanix Objects supports both S3-style path formats:
https://rfdemo.prism-central.cluster.local/objectsdeletedemo
https://objectsdeletedemo.rfdemo.prism-central.cluster.local
We will use the first style, for a very simple reason. I am running this on a Mac without a sophisticated local DNS server, and the host file does not support wildcards. As a fellow lazy admin, I just edited /etc/hosts to point to the HAproxy instead of setting up dnsmasq.
Onwards we go to explore failing over between two Object stores, without touching the client.
When One Store Naps, Another Wakes
For this part of the blog, we set up a second object store. This one has the creative name “rfdemo2”, with the same style of fqdn (rfdemo2.prism-central.cluster.local) as the first. When our client is resolving “rfdemo.prism-central.cluster.local”, it usually returns one of the Load Balancer public IPs (see the original Objects post for a refresher on those LBs). The client connects to that public IP and the request is handled, for example a GET on an object in the “objectsdeletedemo” bucket. However, since we want the client to not realize it has been redirected to a different Object store, our configuration looks slightly different. Our HAproxy is listening on the localhost IP (127.0.0.1), so the hosts file has been edited to resolve rfdemo.prism-central.cluster.local to 127.0.0.1.
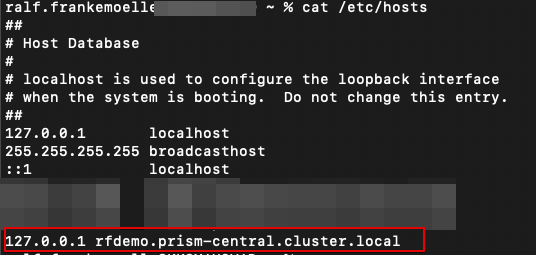
In a real environment, a DNS server entry for the Object store FQDN would point to actual Load Balancers instead of HAproxies bound to localhost. Our client now queries HAproxy instead of the Object store directly. But how do we make that transparent? The second store has a different name (remember, it is rfdemo and rfdemo2). This is where the Multi-FQDN feature in Nutanix Objects comes in. You can navigate to the Object stores and hit the “Manage FQDN & SSL Certificates” button.

In this configuration, we add the new FQDN we want, click “Add FQDN”, and save. Our lab does not have a CA, so we ignore the little red warning on the newly added FQDN. Nutanix Objects checks for valid SSL certificates on all FQDNs. Since this Object store was created as rfdemo2.prism-central.cluster.local, the self-signed certificate only includes the original hostname. In the lab we can skip validation, but do not do this in production.

With this done, our second Object store can now listen on the same FQDN. We are almost there. Now we just need to configure HAproxy to load balance between the Object stores. In the lab we run an active/passive setup, but production environments could run both sites active at the same time.
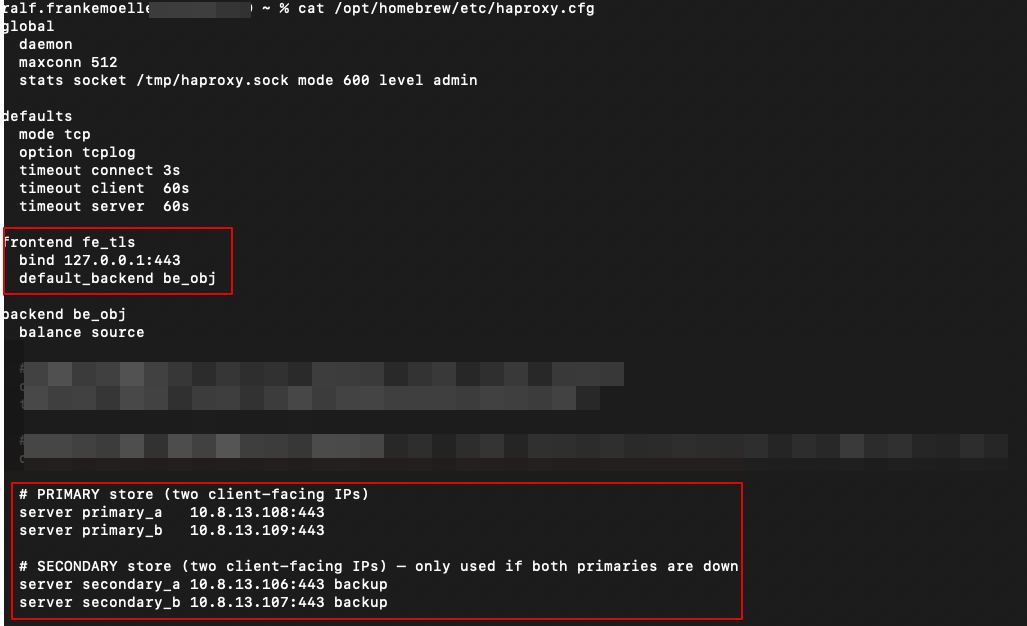
The config is fairly simple: one frontend referring to one backend. The frontend describes the IP and port HAproxy listens on. In this case it is 127.0.0.1:443. As described above, the FQDN rfdemo.prism-central.cluster.local resolves to 127.0.0.1. Since we use HTTPS as the transport for the S3 API calls, requests end up at 127.0.0.1:443. HAproxy then sends them to its backend named “be_obj”. A backend is just a list of IPs or hostnames across which HAproxy can distribute traffic. Here we define primary addresses (the Load Balancer public IPs of rfdemo) and secondary addresses (the Load Balancer public IPs of rfdemo2).
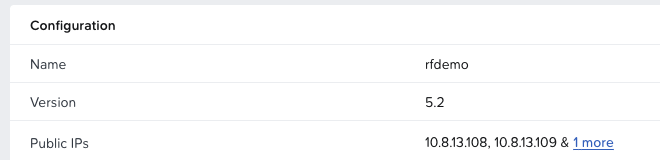
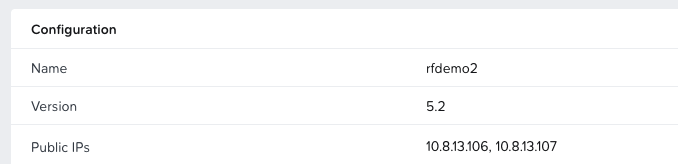
Now for the interesting part. If we query the bucket objectsdeletedemo on rfdemo.prism-central.cluster.local, we should see a file called site1.txt, which indicates we are on the first site represented by the original rfdemo Object store. For reference, we can also check the file in the web client.

Next, we run a query via the terminal against our Object store. This will return anything with a name starting with site.In our case, it simply returns site1.txt, just as we saw in the Object browser before.

To simulate failover, we can either shut off the rfdemo Object store or disable the primary addresses in the HAproxy backend. Since this is a lab and I do not want to wait for the Object store to restart, we disable the primary interfaces and repeat the AWS CLI command. To deactivate, we use these commands:
echo "disable server be_obj/primary_a" | sudo socat - /tmp/haproxy.sock
echo "disable server be_obj/primary_b" | sudo socat - /tmp/haproxy.sock
Yes, not the most elegant, but it gets the job done. To show I am not cheating, I ran the command in the same terminal without clearing the screen. After deactivating the interfaces, the query now returns site2.txt.

Simply reactivating the interfaces will return us to the first site. This demo runs on one cluster and one Prism Central, but the same logic applies across multiple Prism Centrals and Nutanix clusters.
The Buckets that always answered
So, there you have it. Last time in Objectsively Awesome we just dipped our toes in. This round we went full swim class: streaming replication, HAproxy tricks, Multi-FQDN, and a failover that keeps clients blissfully unaware of the chaos backstage. Nutanix Objects proves that high availability really can be low drama.
Now go forth and replicate!